
Decoding DORA ICT Risk Management Requirements: Step 3 - Executing Business Impact Analysis and Risk Assessments
Marc Woolward| December 13, 2023
Share:



Decoding DORA ICT Risk Management Requirements: Step 3 - Executing Business Impact Analysis and Risk Assessments

On our ICT Risk Management journey so far, we have focused on identifying and classifying our ICT assets and mapping them to the systems required to deliver critical business functions (CBFs) and important business services (IBSes).
Now that we have established the ‘Ground Truth’ about our systems (and in particular those required to deliver our most critical business functions), we will use it to ensure we can meet our business’ impact and risk tolerances. This will ensure we continue to deliver the services required by our customers, partners, industry participants, and society as a whole within the required boundaries.
Next, we can effectively begin to manage our risk using the accurate information we have collected.
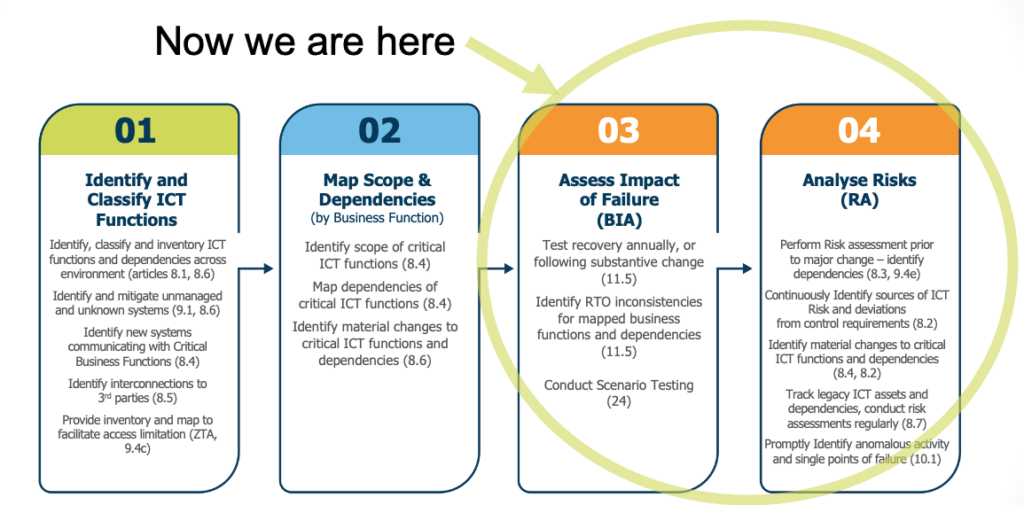
Figure 1: The steps in the ICT Risk Management workflow as defined by the DORA articles (including brief summaries)
The Business Impact Analysis
The Business Impact Analysis (BIA) enables organizations to establish their business’ requirements for availability/recovery of their business functions (known as the Impact Tolerance) and then ensure that their technology, processes, and controls enable them to meet those requirements.
Unlike legacy approaches to business continuity, organizations are also required to consider their ability to recover from a broad set of ‘severe but plausible scenarios’ as opposed to a limited set of classic disaster recovery and business continuity conditions.
In general, the BIA consists of several important stages:
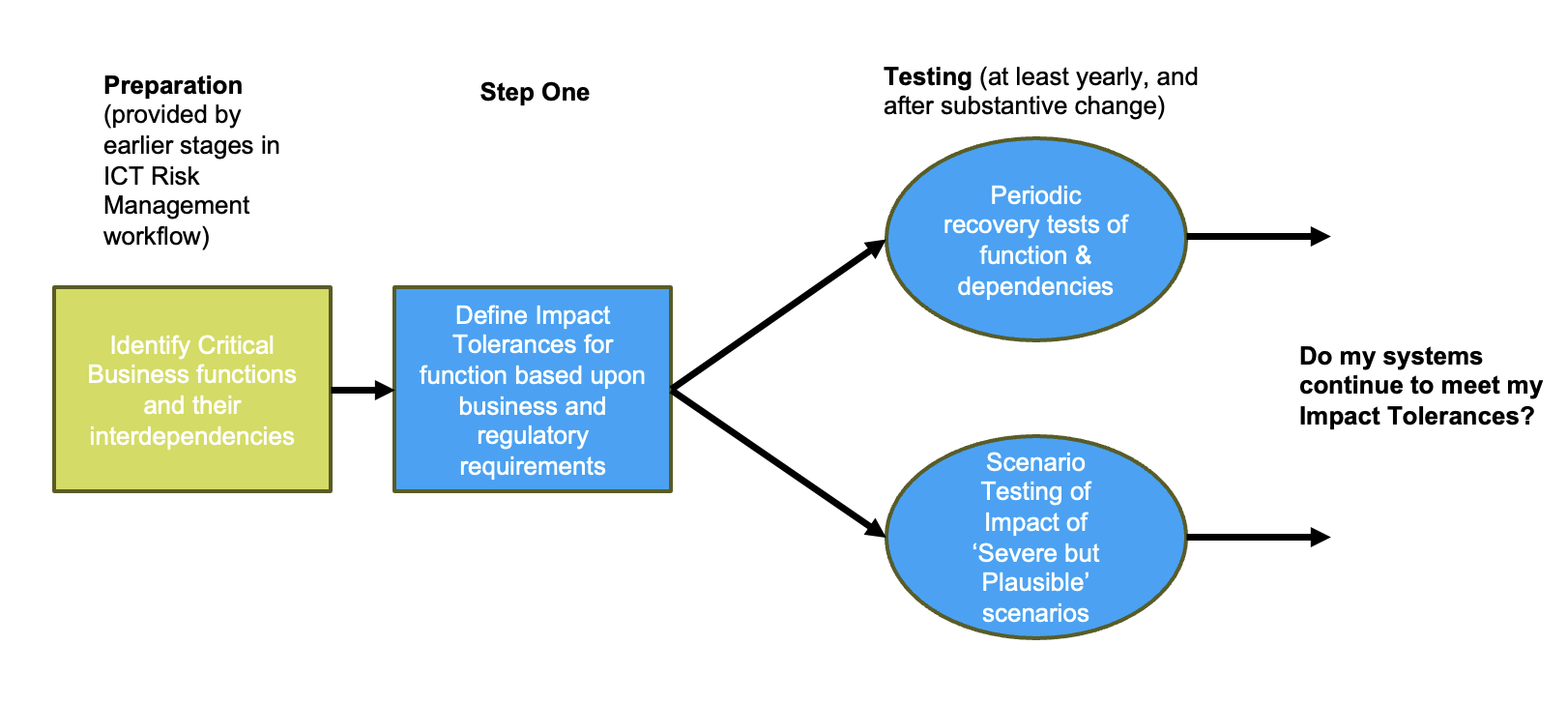
Figure 2: The steps of the BIA process
As we will see, automation and mapping can greatly assist with delivery of this process, and remove many highly disruptive, inaccurate, and expensive manual tests.
Establishing and Testing Impact Tolerances
The impact tolerance of a business function is the maximum level of disruption that can be withstood without causing harm to customers, the institution itself, or the broader system. Beginning the process here allows organizations to test that their systems and processes are capable of meeting the business or regulatory requirement for resilience and availability.
From here, components of the system are analyzed and requirements for recovery time (known as recovery time objective, or RTO) and data persistence (known as recovery point objective, or RPO) are defined. Historically, from this point a simple failover test of the primary application delivering the function would be conducted every year or two. Experience has shown that this approach is insufficient for two important reasons:
- In modern digital businesses, business functions depend upon a complex chain of dependencies. In reality, it is often the failure of a poorly understood or untested interdependency of a primary application which results in significant disruption and the regulators are therefore now particularly focused on ensuring that interdependencies are also tested. Where you have to test the impact of failures across a complex set of interdependencies, this can be highly disruptive and expensive. Accurately mapping recovery capabilities across a set of interdependencies allows organizations to breakdown tests into units, which reduces disruption and facilitates more precise measurement. Additionally, where active/active architectures are deployed across failure domains then observability techniques can be utilized to provide evidence of demonstrated resilience within the runtime environment.
- Infrequent (annual or every two years) testing is insufficient in modern digital environments where material/substantive changes occur frequently across infrastructure, applications, and their complex interdependencies. By utilizing a rules engine which is continuously testing for deviations to impact tolerances and material modifications to application behavior organizations can:
- Immediately identify where application behavior deviates from the baseline (i.e., where a material change has occurred).
- Identify where a change has caused a violation of the impact tolerances in the environment.
Article 12.6
In determining the recovery time and recovery point objectives for each function, financial entities shall take into account whether it is a critical or important function and the potential overall impact on market efficiency. Such time objectives shall ensure that, in extreme scenarios, the agreed service levels are met.
Article 11.6
As part of their comprehensive ICT risk management, financial entities shall:
(a) test the ICT business continuity plans and the ICT response and recovery plans in relation to ICT systems supporting all functions at least yearly, as well as in the event of any substantive changes to ICT systems supporting critical or important functions;
Article 12.1
For the purpose of ensuring the restoration of ICT systems and data with minimum downtime, limited disruption and loss, as part of their ICT risk management framework, financial entities shall develop and document:
(a) backup policies and procedures specifying the scope of the data that is subject to the backup and the minimum frequency of the backup, based on the criticality of information or the confidentiality level of the data;
(b) restoration and recovery procedures and methods.
Article 12.4
Financial entities, other than microenterprises, shall maintain redundant ICT capacities equipped with resources, capabilities and functions that are adequate to ensure business needs. Microenterprises shall assess the need to maintain such redundant ICT capacities based on their risk profile.
The DORA articles require organizations to test that recovery of the full set of interdependencies required to deliver a business function can be achieved in order to remain compliant with impact tolerances, and that testing occurs whenever a material change to the system occurs. This approach is necessary to provide full transparency into the recovery of a system throughout its lifecycle but provides significant challenges to an organization.
vArmour has demonstrated that the following techniques can be applied to mitigate these challenges:
- Identify where material changes occur programmatically.
- To use mapping to ensure that recovery properties remain consistent across complex chains of interdependencies, thereby avoiding the need to test large proportions of an environment at once.
- The continuous monitoring of modern live/live and antifragile application patterns to provide evidence where resilience is demonstrated during normal runtime.
Scenario Testing
Testing for regular systems failure is necessary but insufficient according to DORA and other operational resilience regulations. Organizations also need to regularly test the ability of a business function to remain resilient under a broader set of ‘severe but plausible’ scenarios.
Such scenarios could include:
- Failure of a complete availability zone, exploitation of a security vulnerability.
- Loss of an employee.
- Failure of a critical third party provider.
Scenario testing is the process by which an inventory of severe but plausible scenarios are tested against the systems and processes required to deliver a business function in order to identify weaknesses, risks, and potential concentration risks. This process can be inexact and highly time consuming, however the presence of an accurate and current map can allow organizations to streamline and improve the accuracy of the process:
- By testing the map of the actual runtime systems against specific scenarios (as demonstrated for datacenter failure within our earlier video at 4:20).
- By putting in place rules that can identify immediately detect that an impact tolerance across interdependencies is violated (as demonstrated within the video attached to this article where RTO mismatches are identified).
- By providing a standardized set of tools and information for disparate teams to test their own applications against their business’ requirements allowing central oversight.
Article 12.5
Central securities depositories shall maintain at least one secondary processing site endowed with adequate resources, capabilities, functions and staffing arrangements to ensure business needs.
Article 24.1
For the purpose of assessing preparedness for handling ICT-related incidents, of identifying weaknesses, deficiencies and gaps in digital operational resilience, and of promptly implementing corrective measures, financial entities, other than microenterprises, shall, taking into account the criteria set out in Article 4(2), establish, maintain and review a sound and comprehensive digital operational resilience testing programme as an integral part of the ICT risk-management framework referred to in Article 6.
Article 25.1
The digital operational resilience testing programme referred to in Article 24 shall provide, in accordance with the criteria set out in Article 4(2), for the execution of appropriate tests, such as vulnerability assessments and scans, open source analyses, network security assessments, gap analyses, physical security reviews, questionnaires and scanning software solutions, source code reviews where feasible, scenario-based tests, compatibility testing, performance testing, end-to-end testing and penetration testing.
Risk Assessment
Over the past decade, many high impact systems failures have been caused by poorly executed changes and the presence of poorly understood operational conditions which would have violated standard risk tolerances (for example, a single critical business function being delivered from a single network failure domain).
In both cases, effective Risk Assessment (utilizing accurate and current information) should have enabled the organization to avoid the incident:
- By understanding the interdependencies of a system undergoing change or transformation, it is possible to ensure contingencies and safeguards have been implemented.
- By identifying areas where risk conditions exist, organizations can take steps to remediate these risks prior to an incident (for example, failure of a single network failure domain).
DORA is prescriptive about the need for continuous assessment of risks to business functions.
Article 8.2
Financial entities shall on a continuous basis identify all sources of ICT risk, in particular the risk exposure to and from other financial entities, and assess cyber threats and ICT vulnerabilities relevant to their ICT-related business functions and information assets. Financial entities shall review on a regular basis, and at least yearly, the risk scenarios impacting them.
And also ensuring that material changes are accompanied by a risk assessment.
Article 8.3
Financial entities, other than microenterprises, shall perform a risk assessment upon each major change in the network and information system infrastructure, in the processes or procedures affecting their ICT supported business functions, information assets or ICT assets.
Article 8.7
Financial entities, other than microenterprises, shall on a regular basis, and at least yearly, conduct a specific ICT risk assessment on all legacy ICT systems and, in any case before and after connecting technologies, applications or systems.
Focusing upon anomalous behavior and material deviations from baseline.
Article 10.1
Financial entities shall have in place mechanisms to promptly detect anomalous activities, in accordance with Article 17, including ICT network performance issues and ICT-related incidents, and to identify potential material single points of failure.
In order to meet the requirements for continuous risk assessment, organizations need to develop a highly advanced set of capabilities:
- A highly accurate and up-to-date map of the environment, including the properties of each system.
- The ability to identify both modern and legacy systems and the interconnections between them.
- A method of continuously assessing for anomalous behavior and deviations from the business function’s baseline.
- A method for continuously assessing the map against risk tolerances (risk conditions defined by the organization).
vArmour Relationship Cloud provides the capabilities an organization requires to meet the risk assessment requirements defined by DORA and to automatically advise where risk tolerances have been breached.
Conclusion: The ultimate outcome for an Operational Resilience program is the effective management of impact and risk
This journey has allowed us to explore the challenges presented by modern highly complex digital ecosystems underpinning the modern enterprise. We have spent some time discussing the collection of data, its transformation into usable information, and contextualizing it according to the business function.
In this final article we have demonstrated how this information can enable organizations to proactively manage their resilience, risk, and potential impact of failure.
Without data and automation, this process can be inaccurate, expensive and ultimately futile as human beings attempt to keep up with the constant change present within the modern digital business. By mapping and evaluating complex enterprise environments, tools such as vArmour Relationship Cloud enable organizations to continuously and proactively manage their digital risk and empower risk managers with the information they need to be effective.
I hope you have enjoyed this series of articles and would encourage you to share your thoughts with me at marc@varmour.com. We are also happy to give you a personalized walkthrough of vArmour Application Controller – request a demo here.
Marc Woolward, CTO and CISO
Video Demo
See how to use the vArmour Relationship Cloud to execute, streamline and automate the business impact analysis process and continuous risk assessments that are required by DORA, here.
